Benchmarking with different storage engines using pmemkv
We’re closing out 2017 with two big improvements to pmemkv: support for multiple storage engines, and an improved benchmarking utility based on db_bench. These changes set the stage for some interesting experiments to come next year, as we continue to add new features and tune performance of pmemkv and its utilities and bindings.
Multiple storage engines
A new virtual interface (KVEngine) was recently introduced that allows pmemkv to provide
multiple storage engine implementations, without changes to utilities or language bindings
or applications using the pmemkv API.
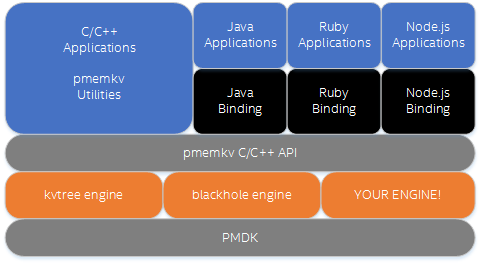
There are two typical motivations for creating a new engine: 1) to try out a significant change to an existing engine while keeping a stable version available or 2) to create an entirely new backing implementation from scratch. In either case, multi-engine support allows new variations to be shared as early as possible, long before the new version is considered complete, but without risk to other storage engines considered stable. Of course, the same can be done with branches or private forks, but we’re betting that incubating all our best new ideas in one place like this will make comparative benchmarking and validation easier for everybody.
Initially pmemkv supports two engines – kvtree for the original single-threaded hybrid
B+ tree, and blackhole for an engine that accepts data but never returns anything. The
blackhole engine is particularly useful for testing the overhead of high-level bindings.
The kvtree engine is used by default when no other engine is specified.
There are several new engines that we’ll be auditioning in 2018, including copy-on-write and multi-threaded implementations. Engine contributions are always welcome if you have an idea to try!
Porting db_bench to pmemkv
Our original pmemkv_stress benchmarking tool has proven quite useful for assessing
performance, but has some limitations:
-
pmemkv_stressonly reports estimated average performance (based on millisecond timings) rather than more accurate histograms (based on nanosecond timings) -
pmemkv_stressdoes not report effective bandwidth usage for each type of benchmark operation -
pmemkv_stressonly supports single-threaded benchmarks (when our roadmap emphasizes multi-threaded operations)
The outcome of these limitations is that pmemkv_stress results can be difficult to line up with
standard db_bench or YCSB benchmark results that we see published elsewhere.
After investigating several different solutions, we’ve successfully ported the db_bench
utility from LevelDB over as a new pmemkv_bench utility that shares many (but not all)
command-line parameters with the original. This pmemkv_bench utility replaces
pmemkv_stress without any loss in functionality. Note that pmemkv_bench has an
engine parameter for easy switching between available engines.
pmemkv_bench
--engine=<name> (storage engine name, default: kvtree)
--db=<location> (path to persistent pool, default: /dev/shm/pmemkv)
--db_size_in_gb=<integer> (size of persistent pool in GB, default: 1)
--histogram=<0|1> (show histograms when reporting latencies)
--num=<integer> (number of keys to place in database, default: 1000000)
--reads=<integer> (number of read operations, default: 1000000)
--threads=<integer> (number of concurrent threads, default: 1)
--value_size=<integer> (size of values in bytes, default: 100)
--benchmarks=<name>, (comma-separated list of benchmarks to run)
fillseq (load N values in sequential key order into fresh db)
fillrandom (load N values in random key order into fresh db)
overwrite (replace N values in random key order)
readseq (read N values in sequential key order)
readrandom (read N values in random key order)
readmissing (read N missing values in random key order)
deleteseq (delete N values in sequential key order)
deleterandom (delete N values in random key order)
One of the best new features here is using --histogram=1 to generate statistical histograms
for each benchmark operation. These include mean, median and detailed tail
latency data, which is all highly informative for benchmarking and tuning.
Why LevelDB?
We chose to port db_bench from LevelDB (even though the RocksDB fork has some nice additions)
because of license compatibility. LevelDB is BSD licensed (like all of PMDK) where RocksDB is GPL.
The pmemkv_bench utility relies on significant code ported from LevelDB. This code is located
in a new leveldb source directory, with all original license and copyright headers intact.
The only modifications to these files are minor cosmetic changes (to defines and includes)
allowing this subset of LevelDB files to be built independently of the entire LevelDB distribution.
Although pmemkv_bench relies on LevelDB sources, no LevelDB source code is used
in other pmemkv utilities or bindings or shared libraries.
We are grateful to Google for this LevelDB code and for choosing such a permissive license for its use.
Conclusion
If you’re using an old version of pmemkv then you really should consider moving to the latest
build to get multi-engine support and the new pmemkv_bench utility. (and be sure to use
--histogram=1 for your future benchmarking!)