Memkind support for KMEM DAX option
Introduction
Linux kernel version 5.1 brings in support for the volatile-use of persistent memory as a hotplugged memory region (KMEM DAX). When this feature is enabled, persistent memory is seen as a separate memory-only NUMA node(s). libmemkind API was extended to include new kinds that allow for automatic detection and allocation from these new persistent memory NUMA nodes.
Requirements
1. Kernel 5.1 with KMEM DAX driver enabled.
If support of KMEM DAX driver isn’t enabled in your kernel you will have to configure
proper driver installation by run nconfig and enable driver.
$ make nconfig
Device Drivers --->
-*- DAX: direct access to differentiated memory --->
<M> Device DAX: direct access mapping device
<M> PMEM DAX: direct access to persistent memory
<M> KMEM DAX: volatile-use of persistent memory
< > PMEM DAX: support the deprecated /sys/class/dax interface2. ndctl and daxctl version 66 or later.
System Configuration
Reconfiguration of Device-DAX depends on dax-bus device model.
Kernel should support /sys/bus/dax model. To migrate it from
/sys/class/dax to /sys/bus/dax model please use daxctl-migrate-device-mode.
Reconfigure DAX devices
The list of available NUMA nodes on the system can be retrieved using numactl.
An example of initial configuration is presented below:
$ numactl -H
available: 2 nodes (0-1)
node 0 cpus: 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83
node 0 size: 80249 MB
node 0 free: 68309 MB
node 1 cpus: 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111
node 1 size: 80608 MB
node 1 free: 71958 MB
node distances:
node 0 1
0: 10 21
1: 21 10To create a namespace in Device-DAX mode as a standard memory from all the available capacity of NVDIMM:
$ ndctl create-namespace --mode=devdax --map=memTo list DAX devices:
$ daxctl list
[
{
"chardev":"dax1.0",
"size":539016298496,
"target_node":3,
"mode":"devdax"
}
]To reconfigure DAX device from devdax mode to a system-ram mode:
$ daxctl reconfigure-device dax1.0 --mode=system-ramAfter this operation, persistent memory is configured as a separate NUMA node and can be used as a volatile memory. For the example configuration below, persistent memory NUMA node is Node 3 (NUMA node without any assigned CPU):
$ numactl -H
available: 3 nodes (0-1,3)
node 0 cpus: 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83
node 0 size: 80249 MB
node 0 free: 68309 MB
node 1 cpus: 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111
node 1 size: 80608 MB
node 1 free: 71958 MB
node 3 cpus:
node 3 size: 512000 MB
node 3 free: 512000 MB
node distances:
node 0 1 3
0: 10 21 28
1: 21 10 17
3: 28 17 10Support in memkind library
Libmemkind supports the KMEM DAX option in three variants. For a better description of memory policies from these variants, see the animations below. The example configuration on which the animations are based on is as follows:
$ numactl -H
available: 4 nodes (0-3)
node 0 cpus: 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83
node 0 size: 80249 MB
node 0 free: 68309 MB
node 1 cpus: 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111
node 1 size: 80608 MB
node 1 free: 71958 MB
node 2 cpus:
node 2 size: 1026048 MB
node 2 free: 1026048 MB
node 3 cpus:
node 3 size: 512000 MB
node 3 free: 512000 MB
node distances:
node 0 1 2 3
0: 10 21 17 28
1: 21 10 28 17
2: 17 28 10 28
3: 28 17 28 10Which corresponds to:
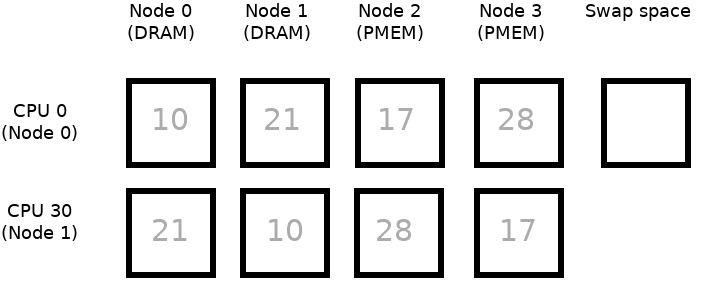
Note:
- Image is simplified to present only 2 CPUs: CPU 0 belongs to Node 0 and CPU 30 belongs to Node 1
- Numbers in squares correspond to NUMA node distances between Nodes 0/1 and all of the Nodes
- Node 0 and Node 1 are based on the DRAM memory whereas Node 2 and Node 3 are based on the NVDIMM memory
- Green frames correspond to currently active CPU and to memory where allocation will go
- Moving physical memory to swap space is limited only to one Node
- To simplify the examples below we assume that the process uses only CPU 0
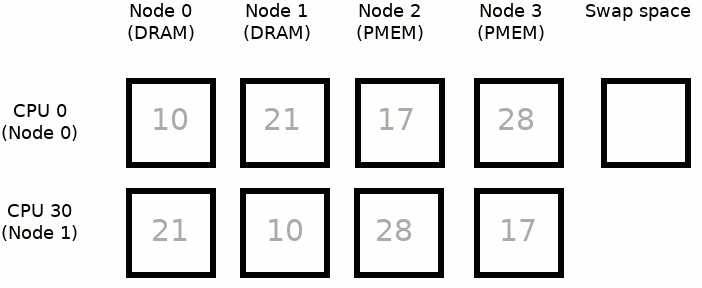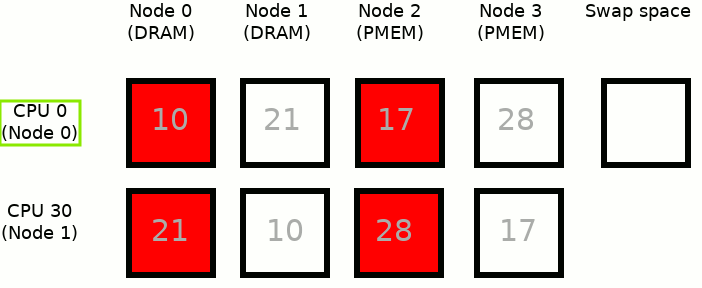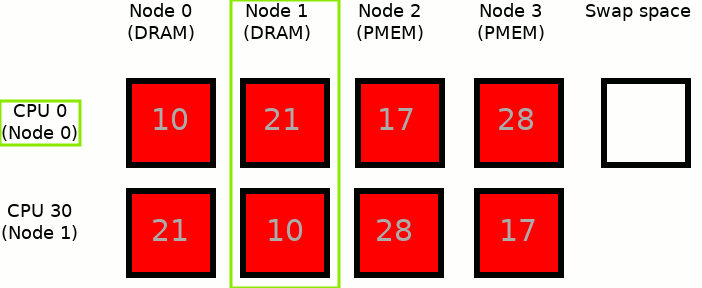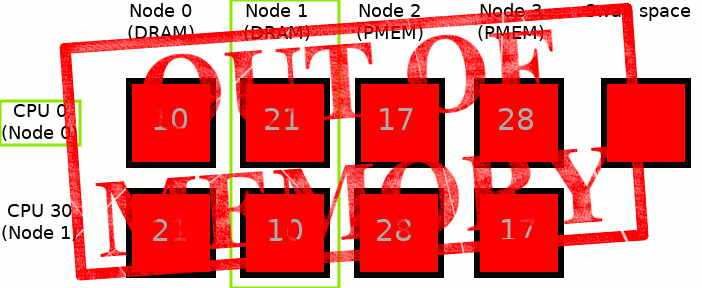
MEMKIND_DAX_KMEM: This is the first variant where memory comes from the closest persistent memory NUMA node at the time of allocation.
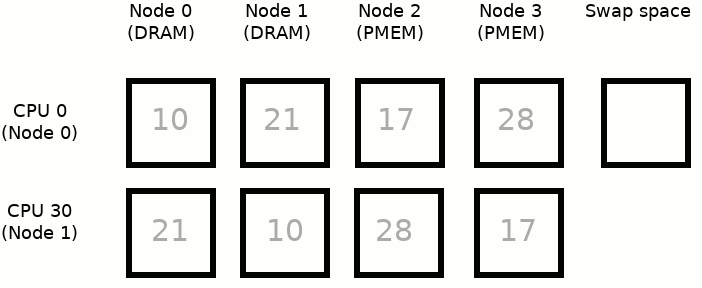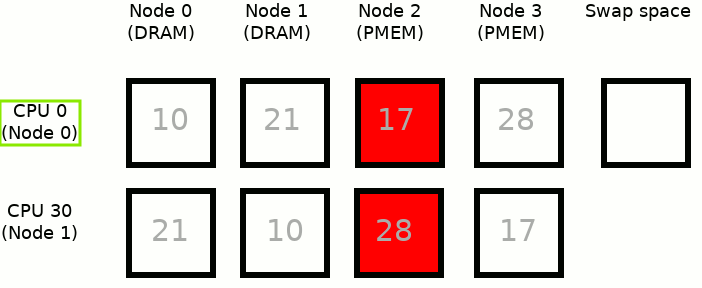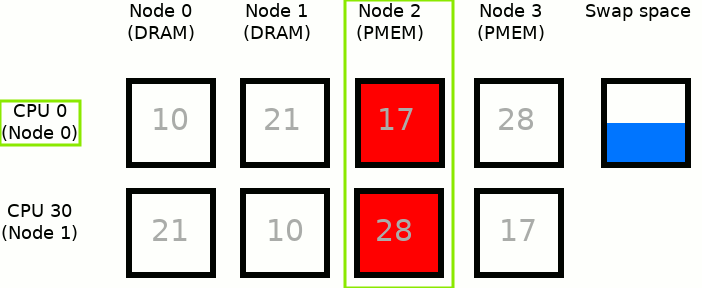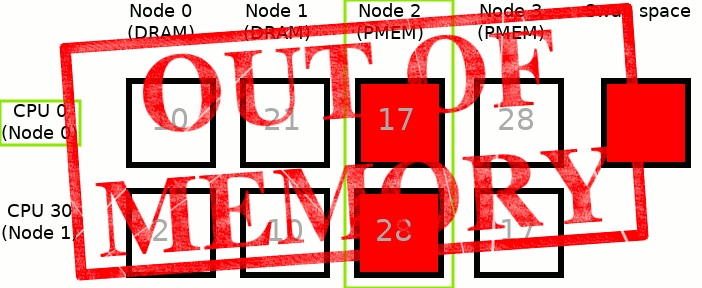
The process runs only on CPU 0, which is assigned to Node 0. Node 2 is the closest persistent memory NUMA node to Node 0, therefore deploying MEMKIND_DAX_KMEM results in taking memory only from Node 2. If there is not enough free memory in Node 2, to satisfy an allocation request, inactive pages from Node 2 are moved into the swap space - freeing up the memory for MEMKIND_DAX_KMEM use case.
MEMKIND_DAX_KMEM_ALL: This is the second variant where the memory comes from the closest persistent memory NUMA node available at the time of allocation.
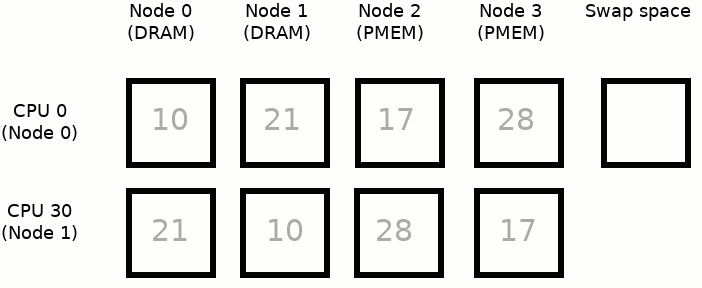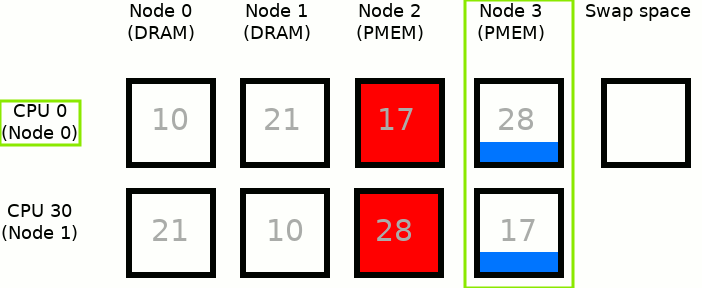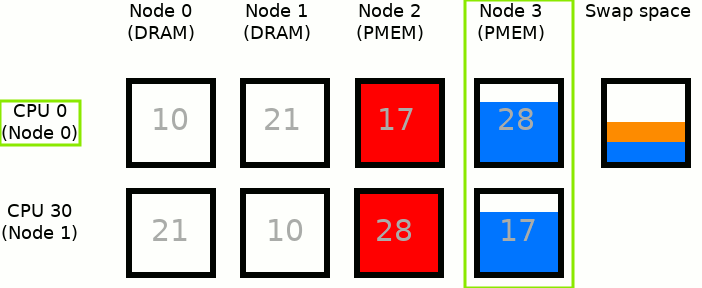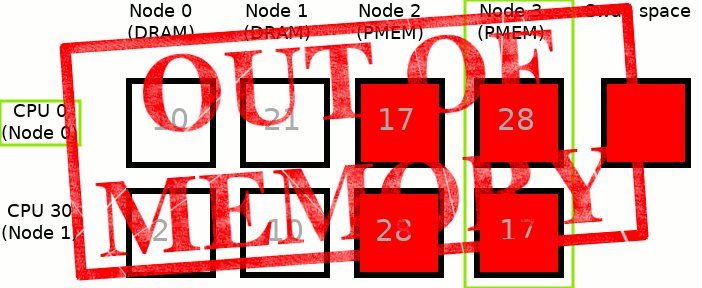
A similar situation to the scenario presented in MEMKIND_DAX_KMEM except that when there is not enough free memory in Node 2, to satisfy an allocation request, the allocation pattern switches to Node 3. When available space is exhausted in Node 3 - swap space is used.
MEMKIND_DAX_KMEM_PREFERRED: This is the third variant where the memory comes from the closest persistent memory NUMA node at the time of allocation. If there is not enough memory to satisfy a request the allocation will fall back on other memory NUMA nodes.
Again the allocation starts from Node 2. When there is not enough free memory in Node 2, the allocation switches to other nodes in order of increase distance from the preferred node based on information provided by the platform firmware: Node 0, Node 3 and ending in Node 1. When available space is exhausted in Node 1 - swap space is used.
Caveats
For MEMKIND_DAX_KMEM_PREFERRED, the allocation will not succeed if two or more persistent memory NUMA nodes are in the same shortest distance to the same CPU on which the process is eligible to run. A check on that eligibility is performed upon starting the application.
Environment variable
MEMKIND_DAX_KMEM_NODES is an environment variable - a comma-separated list of NUMA nodes that are treated as persistent memory. This mechanism is dedicated to override the automatic mechanism for detecting the closest persistent memory NUMA nodes.
Example usage with memkind library
Leveraging new kinds is similar to the usage presented in the previous post
with one exception that the kinds presented in this post do not need to be created first with memkind_create_pmem() method.
With libmemkind, it is possible to distinguish the physical placement of an allocation:
- MEMKIND_DAX_KMEM allocation goes to NVDIMM
- MEMKIND_REGULAR allocation goes to DRAM