Glossary of Terms
Here you’ll find a list of terms related to Persistent Memory (PMem). Many of these terms have a broader meaning, but the definitions below focus specifically on their relationship to PMem.
Click on the term to go to the definition in this page, or scroll down to read them all. Related terms are shown in parentheses.
| Compute Express Link™ and CXL™ are trademarks of the CXL Consortium. Intel® and Intel® Optane™ are trademarks of Intel Corporation. JEDEC® is a trademark of the JEDEC Organization. SNIA® is a trademark of the Storage Networking Industry Association. |
Contents
- 1LM (One-level Memory)
- 2LM (Two-level Memory)
- 3D XPoint
- ADR (Asychronous DRAM Refresh)
- App Direct (Application Direct)
- ARS (Address Range Scrub)
- Bad Blocks
- Blast Radius
- Block Storage (Storage, Disk)
- BTT (Block Translation Table)
- CLFLUSHOPT (Instruction: Cache Line Flush, Optimized)
- CLWB (Instruction: Cache Line Write Back)
- CXL (Compute Express Link)
- DAX (Direct Access)
- DDR (Double Data Rate)
- DDR-T
- Device DAX (devdax)
- Dirty Shutdown Count (DSC, Unsafe Shutdown Count)
- DRAM (Dynamic Random Access Memory)
- DSM (Device Specific Method, _DSM)
- eADR (Extended ADR)
- Fence (SFENCE)
- FlushViewOfFile (Windows Flush System Call)
- Interleave Set
- KMEM DAX
- Label Storage Area (LSA)
- libmemkind
- libpmem
- libpmem2
- libpmemblk
- libpmemkv
- libpmemlog
- libpmemobj
- librpma
- LLPL (Java Low Level Persistence Library)
- MapViewOfFile (Windows Memory Map System Call)
- Memory Mode (2LM)
- Memory Pooling
- Memory Tiering
- mmap (POSIX Memory Map System Call)
- msync (POSIX Flush System Call)
- Namespace
- ndctl
- NFIT (NVDIMM Firmware Interface Table)
- NT Store (Non-Temporal Store)
- NVDIMM (Non-Volatile Dual In-line Memory Module)
- NVM (Non-Volatile Memory)
- Optane (DCPMM, DCPM)
- Paging
- PCJ (Persistent Collections for Java)
- Persistence Domain (Power Fail Safe Domain)
- Persistent Memory (PMem, pmem, PM)
- PMDK (Persistent Memory Development Kit)
- PMem Programming Model
- pmemhackathon (Persistent Memory Programming Workshop)
- PMoF (Persistent Memory over Fabrics)
- Poison
- Pool
- Poolset
- Programming Model
- Region
- RPMEM (Remote Persistent Memory)
- SNIA (Storage Networking Industry Association)
- Storage Class Memory (SCM)
- Transaction
- Uncorrectable Error
1LM
(One-level Memory)
The term 1LM refers to how memory is usually connected to the system, without any memory-side cache. Normally, the terms DRAM or system main memory are used, but 1LM is sometimes used to specifically state that the memory in question is not configured as 2LM.
2LM
(Two-level Memory)
Persistent memory is sometimes configured as 2LM where hardware manages two levels (tiers) of memory. This is a feature of the Intel’s Optane PMem, which calls this configuration Memory Mode (more detail in that glossary entry).
3D XPoint
3D XPoint (pronounced three dee cross point) is the media used in Intel’s Optane product line, where the media is organized into Solid State Disk (SSD) products, and Persistent Memory (PMem) products. More details can be found on Intel’s website. There is also a fairly extensive Wikipedia entry for it.
 |
|---|
| 3D XPoint |
ADR
(Asychronous DRAM Refresh)
ADR is the hardware feature that flushes stores from the memory controller write pending queue (WPQ) to their destination on power loss. ADR can optionally flush pending DMA stores from the I/O controller as well.
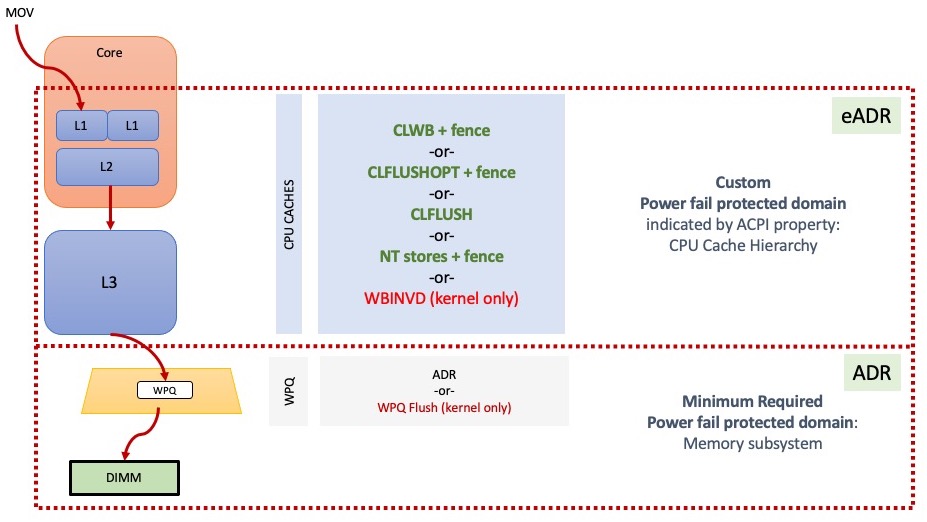
As shown in the above diagram, there are multiple places a store could reside on its way to a persistent memory DIMM. The lower dashed red box shows the ADR domain – stores that reach that domain are protected against power failure by ADR, which flushes the queues in the memory controller, shown as the trapezoid in the diagram. All Intel systems supporting persistent memory require ADR, which means the feature must be supported at the platform level (including CPU, motherboard, power supply, DIMM, and BIOS). All NVDIMM-N products, as well as Intel’s Optane PMem, require systems that support ADR.
ADR uses stored energy to perform the flushes after power loss. The stored energy typically comes from capacitors in the power supply, but could be implemented other ways such as a battery or UPS.
The larger red dashed box in the diagram illustrates an optional feature, eADR, where the CPU caches are also flushed on power loss.
App Direct
(Application Direct)
Intel’s Optane PMem product can be provisioned into two modes: App Direct and Memory Mode. See Intel’s website for product details. The App Direct mode provides the persistent memory programming model.
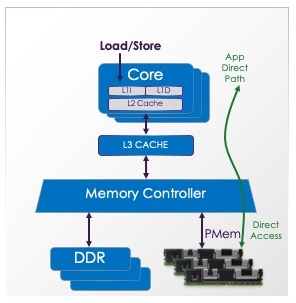
When configured this way, the OS can provide direct access or DAX to persistent memory aware applications. This allows applications to access the persistence just like memory, with loads and stores.
ARS
(Address Range Scrub)
NVDIMM products may provide an interface that allows the operating system to discover the known poison locations on the device. Knowing about these bad blocks ahead of time allows applications to avoid consuming poison, thereby avoiding the associated exception that typically kills the application.
The ARS interface is exposed as a DSM. The DSM for Address Range Scrub is described by the ACPI specification, available on the UEFI web site.
Bad Blocks
The OS may track a list of known bad blocks on a persistent memory device. These blocks may be discovered using the Address Range Scan (ARS) operation supported by some NVDIMMs, or they may be discovered on the fly when software tries to use a location and is returned poison instead.
For normal volatile memory (i.e. DRAM) on a server class machine, an uncorrectable error will result in a poison value returned to the application that consumes it. On Intel platforms, consuming poison causes a machine check which, in turn, will cause the kernel to send an exception to the process consuming the poison. On Linux, the exception takes the form of a SIGBUS signal, and most applications will die as a result. On restart, the problem is gone since the application starts allocating volatile memory from scratch and the OS will have sequestered the page containing the poison.
Persistent memory adds complexity to this case. Poison consumption results in the same SIGBUS in the Linux example above, but if the application dies and restarts it is likely to return to reading the same location since there’s an expectation of persistence – the OS can’t just replace the old page with a new one like it can for volatile memory since it needs the poison to remain there to indicate the loss of data.
ECC information, which is used to detect uncorrectable errors, is typically maintained for each cache line, which on an Intel system is 64-bytes. But that small range can be rounded up to a larger range due to the blast radius effect.
To prevent the ugly behavior where a PMem-aware application repeatedly starts up, consumes poison, and dies, the OS provides a way for the application to access the list of known bad blocks. On Linux, the ndctl command can be used to view this information as well:
# ndctl list --media-errors
An API provided by libndctl allows applications to access this information directly, and the PMDK libraries use that API to prevent opening a PMem pool when it contains known bad blocks. The common action taken by an application in this case is to refuse to continue, forcing the system administrator to restore the pool data from a backup or redundant copy. Of course it is possible for the application to attempt to repair the pool directly, but that leads to much more complex application logic.
Intel’s PMem RAS page contains more information on this topic, focused on the Optane PMem product.
Blast Radius
When a location of persistent memory experiences an uncorrectable error, that data is lost. Memory on Intel platforms is accessed as 64-byte cache lines, but there are cases where losing a single location can cause an application to lose a larger block of data. This is known as the blast radius effect.
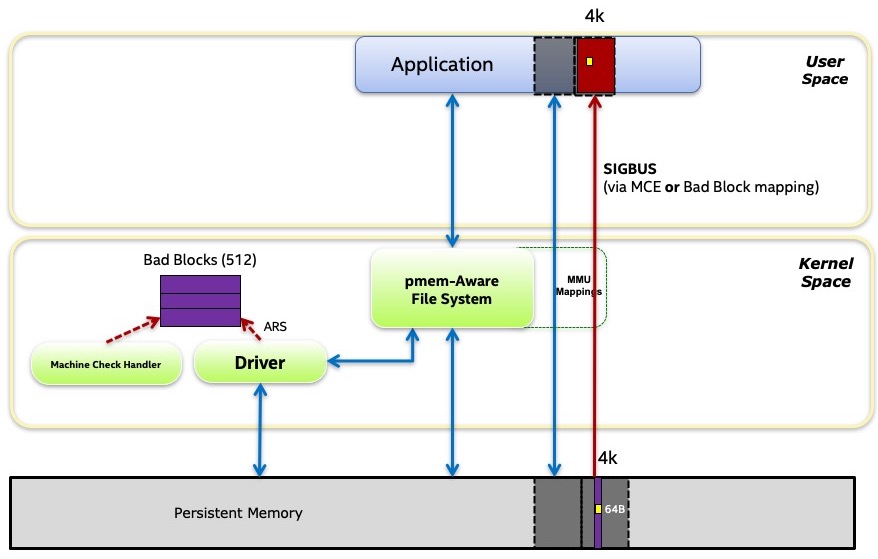
As shown in the above diagram, a 64-byte location containing poison (due to an uncorrectable error, for example), may get its size rounded up by the device to whatever that device uses as its ECC block size. The Linux operating system can learn about these bad locations via the address range scrub mechanism. Linux tracks these areas using a bad block tracking data structure in the kernel that tracks 512-byte blocks, so the size will be rounded up to 512-bytes by that. If the application memory maps the file, the OS will map an invalid page at that location, again rounding the size up to the larger value of 4096-byte (the page size on Intel systems).
Block Storage
(Storage, Disk)
When comparing traditional storage to persistent memory, these are the primary differences:
-
The interface to block storage is block-based. Software can only read a block or write a block. File systems are typically used to abstract away this detail by paging blocks to/from storage as required.
-
The interface to PMem is byte-addressable. Software can read or write any data size without the need for paging. Persistent data are accessed in-place, reducing the need for DRAM to hold buffered data.
-
When a use case does want to move a block, such as 4k of data, block storage devices like NVMe SSDs initiate DMA to memory. This allows the CPU to perform other work while waiting for the data transfer.
-
PMem is typically implemented as an NVDIMM, connected to the memory bus, which cannot initiate DMA. To move 4k of data, the CPU usually moves the data, which is lower latency than a storage device but results in higher CPU utilization. One potential solution to this is to use a DMA engine if the platform provides one.
-
PMem can emulate a block storage device and in fact, that is part of the PMem programming model. Block storage cannot emulate PMem since it is fundamentally not byte-addressable. Paging can get close to emulating PMem, especially for fast SSDs, but flushing changes to persistence will still require executing kernel code with block storage, where PMem can flush to persistence directly from user space (see ADR and eADR for details).
Also see BTT for details on how PMem emulates block storage.
BTT
(Block Translation Table)
The BTT algorithm provides single block powerfail write atomicity on top of persistent memory. This allows PMem to emulate storage and provide similar semantics to NVMe. NVMe storage requires at least one block powerfail write atomicity, meaning a block being written during a power failure will either be fully written or not written at all. Since software may depend on this attribute of storage, the BTT algorithm was designed to implement the same semantics in software. The algorithm was standardized as part of UEFI.
For an introduction on how BTT works, shorter than reading the full specification, see this blog, written by the Linux maintainer of its BTT implementation, Vishal Verma.
CLFLUSHOPT
(Instruction: Cache Line Flush, Optimized)
The Intel instruction set has long contained a cache flush
instruction, CLFLUSH, which will evict a specific cache line
from the CPU caches. The definition of CLFLUSH, which pre-dates
persistent memory, includes a fence
as part of the instruction. This means that a loop of CLFLUSH
instructions, intended to flush a range
of cache lines, will be serialized due to the fence between each
flush.
 With the advent of persistent memory, Intel introduced
the CLFLUSHOPT instruction, which is optimized by removing
the embedded fence operation. As a result, a loop of CLFLUSHOPT
instructions will launch the flushes, allowing for some parallelism
of the flushes. Such a loop should be terminated with a final
fence to ensure completion before software continues under
the assumption that the stores in that range are persistent.
With the advent of persistent memory, Intel introduced
the CLFLUSHOPT instruction, which is optimized by removing
the embedded fence operation. As a result, a loop of CLFLUSHOPT
instructions will launch the flushes, allowing for some parallelism
of the flushes. Such a loop should be terminated with a final
fence to ensure completion before software continues under
the assumption that the stores in that range are persistent.
The CLFLUSHOPT instruction always evicts the cache line, meaning the next access to that address will be a CPU cache miss, even if it happens very soon after the flush. Compare this with the CLWB instruction, which allows the line to remain valid.
CLWB
(Instruction: Cache Line Write Back)
The CLWB instruction is the preferred way to flush
PMem stores to persistence, when required by the platform.
This is the case for platforms that only support ADR.
Platforms that support eADR allow software to skip
the CLWB instructions for better performance.
Unlike the CLFLUSH and CLFLUSHOPT instructions,
CLWB tells the CPU it is desirable to leave the cache line
valid in the CPU cache after writing our any dirty data. This
provides better performance for the cases where the application
accesses the line again, soon after flushing.
Like CLFLUSHOPT, the CLWB instruction does not contain an implied fence, so after flushing a range using this instruction, it is typical to issue an SFENCE instruction.
CXL
(Compute Express Link)
Quoting from the CXL web site, Compute Express Link™ (CXL™) is an industry-supported Cache-Coherent Interconnect for Processors, Memory Expansion and Accelerators.
For persistent memory, CXL offers a new attach point. The CXL 2.0 specification, published in November 2020, includes the necessary support for PMem, including changes for management, configuration, namespace and regions labels, and a flush-on-fail mechanism similar to eADR (called GPF for Global Persistent Flush in CXL terminology).
For PMem-aware application programmers, the most important aspect of CXL is that the PMem programming model remains unchanged. A program written for an NVDIMM-based PMem product will work without modification on a CXL-based PMem product.
The 2021 PM+CS Summit (April 22, 2021) contained this talk which provides a brief overview of the changes made to CXL in support of PMem.

DAX
(Direct Access)
The PMem programming model states that applications can directly map persistent memory using the standard memory mapped files API provided by the OS. This feature, where system calls like mmap and MapViewOfFile bypass the page cache, has been named DAX in both Linux and Windows. DAX is short for direct access and is a key feature added to the operating systems in support of persistent memory.
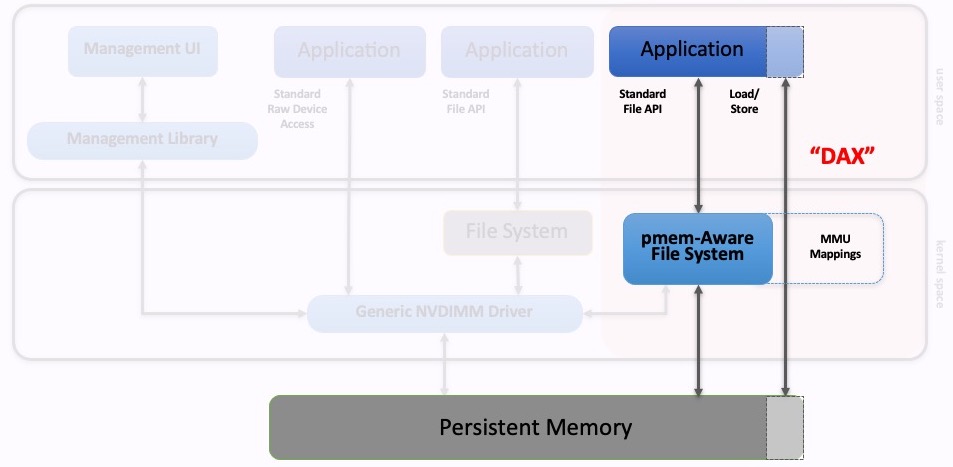
As shown in the above diagram, an application uses standard APIs to open a file and then memory map it. The job of the PMem-aware file system is to provide the DAX mapping, so that no paging occurs as the application accesses the memory range.
In order to make stores to PMem persistent, the standard API for flushing
may be used: (msync on Linux, or FlushViewOfFile
on Windows). The programming model also allows for user space flushing
to persistence directly using instructions like CLWB, but this is
only allowed on Linux if mmap is successfully called with the MAP_SYNC
flag. On Windows, all DAX mappings allow flushing from user space.
The Linux doc on DAX contains additional information about DAX on Linux.
DDR
(Double Data Rate)
The term DDR is a generalization of the various versions of the DDR protocol. For example, DDR4 is explained here on Wikipedia.
When talking about persistent memory, this term is used to talk about what types of memory are plugged into what types of sockets. For example, NVDIMM-N products typically plug into DDR sockets, like normal DRAM. Intel’s Optane PMem plugs into DDR sockets but runs the DDR-T protocol over the DDR electricals.
DDR-T
DDR-T is the protocol used on Intel platforms with their Optane PMem products, which plug into the system’s DDR slots.
Device DAX
(devdax)
Linux supports DAX, which allows a PMem-aware file system to
give applications direct access to PMem when they memory map a file.
Linux also supports DAX without using a file system via a configuration
known as device DAX. The Linux ndctl command uses the terms
fsdax and devdax to choose between these two types of DAX, as
described in the
ndctl-create-namespace
man page.
In most cases, the ability to manage PMem like files, including naming, permissions, and POSIX file APIs, makes fsdax the preferred choice. devdax does not follow the PMem programming model since the normal file APIs do not work with it. Here are the main differences between fsdax and devdax on Linux:
-
In both cases, fsdax and devdax, the normal I/O path is load and store instructions which allow access directly from user space, with no kernel code in the data path.
-
devdax exposes the entire namespace as a single device, since there’s no file system to divide the space into named files.
-
The lack of file system also means the lack of file permissions, so devdax requires either running the application as root, or changing permissions on the device itself.
-
devdax provides more raw access to the PMem, so it is easier for an application to guarantee alignment for large pages. This is the most common reason for an application to use devdax, as described by RedHat in this page.
-
When the system knows about bad blocks in PMem, fsdax will map invalid pages in those areas to prevent applications from consuming poison. Consuming poison on Intel servers causes machine checks which can be difficult to deal with. devdax access is more raw, allowing pages containing poison to be mapped so applications will experience machine checks when they touch those areas, even if the poison is already known to the system.
-
devdax allows long-lived RDMA memory registrations, like those required by some RDMA-based libraries. This is the next most common reason for an application to use device DAX. With fsdax, long-lived memory registrations are disallowed, and only RDMA cards that support On-Demand Paging (ODP) will work.
-
devdax does not implement all of POSIX. For example, msync does not work and user space flushing with instructions like CLWB must be used instead. Finding the size of the PMem is more complex than just calling
stat(2), but the PMDK libraries abstract away these differences and work with devdax as expected. -
Since devdax does not include a file system, the usual security provided by a file system, where allocated blocks are zeroed, is not provided. This means applications can see old data left there from previous runs so the application designer must take this into account.
PMDK provides a utility, daxio for saving/restoring/zeroing a devdax device.
Dirty Shutdown Count
(DSC, Unsafe Shutdown Count)
Flush-on-fail mechanisms like ADR and eADR provide a programming model for PMem by transparently ensuring stores reach persistence even in the face of sudden power loss. When the flush-on-fail mechanism itself fails, the promise made to software no longer holds true and some unflushed stores may have been lost. This is a rare occurrence, typically the result of a hardware fault, but obviously it must be reported to software to avoid silent data corruption. The dirty shutdown count is the way this failure is reported to software.
When a PMem-aware application starts using a PMem file, it looks up the current dirty shutdown count and stores it in the header information for that file. Each time the file is opened, the current count is checked against the stored count to see if a dirty shutdown has happened. If one has happened, the application should consider the file in an unknown state. Applications may attempt to repair the file, but the most common action is to consider the file lost and to restore it from a redundant source such as a back up copy.
The PMDK libraries store and check the dirty shutdown count as described above and will refuse to open any pools that fail the check.
DRAM
(Dynamic Random Access Memory)
DRAM is the traditional main memory connected to virtually all computers today.
Persistent memory can be made out of DRAM, which is exactly what the NVDIMM-N products on the market do. With NVDIMM-N, the PMem runs at DRAM speeds because it is actually DRAM, and when power is lost, the NVDIMM-N saves the data persistently on a NAND flash chip.
Persistent memory can be made out of other media types which are not DRAM. Intel’s Optane PMem uses 3D XPoint as its media, for example.
The comparison between NVDIMM-N and Intel’s Optane points out that whether or not a product is considered PMem is more about the programming model it provides, rather than which media type it uses to implement that model.
DSM
(Device Specific Method, _DSM)
ACPI defines the notion of a Device Specific Method, often written as _DSM, which allows the pre-boot environment to abstract away some hardware details and provide a uniform interface for the OS to call. The standard DSMs for NVDIMMs are described by the ACPI specification, available on the UEFI web site. In addition, Intel has published the DSM Interface for Optane (pdf).
eADR
(Extended ADR)
eADR is the hardware feature that flushes stores from the CPU caches and memory controller write pending queues (WPQ) to their destination on power loss.
As shown in the above diagram, there are multiple places a store could reside on its way to a persistent memory DIMM. The lower dashed red box shows the ADR domain – stores that reach that domain are protected against power failure by ADR, which flushes the queues in the memory controller, shown as the trapezoid in the diagram. All Intel systems supporting persistent memory require ADR. The larger red dashed box in the diagram illustrates an optional platform feature, eADR, where the CPU caches are also flushed.
eADR uses stored energy to perform the flushes after power loss.
The BIOS notifies the OS that CPU caches are considered persistent using a field in the NFIT table. In turn, the OS typically provides an interface for applications to discover whether they need to use cache flush instructions like CLWB or whether they can depend on the automatic flush on power failure provided by eADR. Using PMDK will allow an application to check for eADR automatically and skip cache flush instructions as appropriate.
Fence
(SFENCE)
The term fence refers to ordering instructions that programmers typically use to order operations to memory. For the Intel architecture, the intricate details of the fence instructions are described in the Software Development Manuals (SDM). For persistent memory programming, the SFENCE instruction is particularly interesting. The ordering properties of SFENCE are described by Intel’s SDM as follows:
The processor ensures that every store prior to SFENCE is globally visible before any store after SFENCE becomes globally visible.
For systems with eADR, where global visibility means persistence, the SFENCE instruction takes on a double meaning of making the stores both visible to other threads and persistent.
For ADR systems, where cache flushing is required to make stores persistent, it is necessary to ensure that flushed stores have been accepted by the memory subsystem, so that they may be considered persistent. Cache flush instructions like CLWB are launched and run asynchronously. Before software can continue under the assumption that the flushed range is persistent, it must issue an SFENCE instruction.
Libraries like PMDK are designed to abstract away the details of complex instructions like SFENCE, in order to make PMem programming easier for application developers.
FlushViewOfFile
(Windows Flush System Call)
One principle of the PMem programming model is that standard file APIs work as expected on PMem files. For Windows, the standard API for memory mapping a file is MapViewOfFile and the standard way to flush any stores to that range to make them persistent is FlushViewOfFile.
On Windows, when a PMem file is DAX mapped, it is also possible to flush stores directly from user space using flush instructions like CLWB. This is typically much faster than using the system calls for flushing, but both will work.
It is important to note that, according to Microsoft’s documentation, FlushViewOfFile may return before the flushing is complete, so it is common to call FlushFileBuffers after using FlushViewOfFile.
FlushViewOfFile on Windows is roughly equivalent to msync on POSIX systems.
Interleave Set
The Interleaved Memory entry on Wikipedia describes how interleaving is used for performance, similar to striping across disks in a storage array. For persistent memory, there’s another consideration. Since PMem is persistent, the interleave set must be constructed the same way each time the PMem is configured by the system, or else the persistent data will appear garbled to software.
Exactly how PMem interleave sets are created the same way each time is a product specific detail for NVDIMMs. For persistent memory on CXL, a standard mechanism for this has been defined: region labels. These labels are stored persistently in a label storage area, also defined by the CXL specification.
An interleave set is also called a region by Linux, as well as by the CXL specification.
KMEM DAX
KMEM DAX is a semi-transparent alternative to Memory Mode for volatile use of PMem. Device DAX can be configured in system-ram mode. This mode exposes PMem as a hotplugged memory region. Configured this way, Persistent Memory takes the form of a separate memory-only NUMA Node(s). In contrast to Memory Mode, PMem is represented as an independent memory resources explicitly managed by the Operating System. For more information about KMEM DAX, see KMEM DAX blog post.
Label Storage Area
(LSA)
Persistent memory devices, such as NVDIMMs, can be carved into logical partitions known as namespaces. The ACPI specification describes a standard way to manage namespaces by creating namespace labels and storing them in a label storage area (LSA).
The CXL specification extends the LSA idea to store both namespace labels and region labels.
Typically the LSA is a fairly small, reserved area, in the tens of kilobytes in size. It is persistent and the rules for reading and writing it are specified in a way that helps detect errors, such as a missing device in an interleave set.
libmemkind
The memkind library is focused on the volatile use of PMem, where software ignores the persistence aspect of the PMem and uses it for its capacity and price point. memkind uses the popular jemalloc library internally to offer a flexible allocator for multiple, independent heaps. More information can be found on the memkind web page.
libpmem
The libpmem library provides low level persistent memory support. Higher level libraries like libpmemobj were implemented on top of libpmem until the newer libpmem2 came along. The PMDK page contains documentation on all the PMDK libraries, which are open source and available on GitHub.
libpmem2
The libpmem2 library provides low level persistent memory support, and is a replacement for the original libpmem library. libpmem2 provides a more universal and platform-agnostic interface. Developers wishing to roll their own persistent memory algorithms will find this library useful, but most developers will likely use libpmemobj which provides memory allocation and transaction support. Higher level libraries like libpmemobj are implemented on top of libpmem2. The PMDK page contains documentation on all the PMDK libraries, which are open source and available on GitHub.
libpmemblk
The libpmemblk library supports arrays of pmem-resident blocks, all the same size, that are atomically updated. For example, a program keeping a cache of fixed-size objects in pmem might find this library useful. The algorithm used by libpmemblk is the same as the BTT algorithm standardized as part of the UEFI specification. The PMDK page contains documentation on all the PMDK libraries, which are open source and available on GitHub.
libpmemkv
The libpmemkv library provides a local/embedded key-value datastore optimized for persistent memory. Rather than being tied to a single language or backing implementation, pmemkv provides different options for language bindings and storage engines. The PMDK page contains documentation on all the PMDK libraries, which are open source and available on GitHub.
libpmemlog
The libpmemlog library provides a PMem-resident log file. This is useful for programs like databases that append frequently to a log file. The PMDK page contains documentation on all the PMDK libraries, which are open source and available on GitHub.
libpmemobj
The libpmemobj library is the most popular and powerful library in the PMDK collection. It provides a transactional object store, providing memory allocation, transactions, and general facilities for persistent memory programming. Developers new to persistent memory probably want to start with this library. The PMDK page contains documentation on all the PMDK libraries, which are open source and available on GitHub.
librpma
The librpma provides an API for remote persistent memory access. This PMDK library is designed to help applications use RDMA to access remote PMem.
See the librpma man page for details.
LLPL
(Java Low Level Persistence Library)
LLPL is the Java Low Level Persistence Library offering access to blocks of persistent memory allocated on a persistent heap. More information can be found on the LLPL GitHub Page.
MapViewOfFile
(Windows Memory Map System Call)
The Windows file API includes the ability to memory map a file using the system call MapViewOfFile.
A memory mapped file appears as a range of virtual memory in the application’s address space, allowing the application to access it like memory with loads and stores. For files on storage, this works because the OS uses paging to bring the contents of a page into DRAM when the application accesses that page. For persistent memory, a PMem-aware file system allows a memory mapped file to access the PMem directly, a feature known as DAX.
The Windows documentation contains the details on how to use this system call.
The equivalent system call on POSIX based systems (like Linux) is mmap.
Memory Mode
(2LM)
Intel’s Optane PMem product can be provisioned into two modes: App Direct and Memory Mode. See Intel’s website for product details. Here we describe enough about Memory Mode to provide an overview of how it pertains to persistent memory in general.
Memory Mode combines two tiers of memory, DRAM and PMem, and it is sometimes referred to as 2LM or two-level memory.
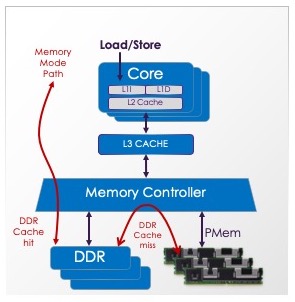
When configured this way, the system DRAM acts as a memory-side cache. When an access is a cache hit, the data is returned from DRAM (Near Memory) at DRAM performance. When an access is a cache miss, the data is is fetched from PMem (Far Memory) at PMem performance. Intel’s Memory Mode uses a 64-byte cache line size in the memory side cache.
Memory Mode is a volatile use of persistent memory – there’s no expectation by software that the memory range is persistent and, in fact, the Optane PMem device cryptographically scrambles the data on each boot to ensure the expected volatile semantics.
Although this 2LM configuration is technically possible between any two tiers of memory, its primary popularity is to provide a high-capacity system main memory without incurring the cost of DRAM for the entire capacity.
Memory Pooling
In this glossary, we use the term Memory Pooling to refer to the disaggregation of memory into a shared pool, such that memory could be assigned to different hosts that are physically connected to the pool. The reason to use Memory Pooling is to more efficiently leverage the memory capacity among a group of machines, avoiding stranded memory where a host’s compute resources are exhausted while having unused memory capacity. Typically, an orchestrator determines the optimal use of resources in a group of machines, and with Memory Pooling, that would include the assignment of memory capacity to individual hosts.
The CXL 2.0 specification includes some support for Memory Pooling.
Do not confuse this term with Memory Tiering, which is a different concept. Memory Pooling is about sharing capacity between multiple hosts, where Memory Tiering is how a host chooses to use multiple types of memory available to it.
Note that the term Memory Pool is also in common use and is unrelated to the concept described here.
Memory Tiering
The term Memory Tiering refers to data placement between multiple types of memory in order to take advantage of the most useful attributes of each type. For example, tiering between DRAM and Optane is done to leverage the higher performance of DRAM with the cheaper capacity of Optane. The most common reason for Memory Tiering configurations is cost reduction because if cost isn’t an issue, one could just populate the entire system with the fastest type of memory available. However, in some cases tiering is used to provide capacities otherwise unavailable, for example creating a 6 TB main memory system using 512 GB Optane modules when 512 GB DRAM modules are not yet available.
Memory Tiering can be done by modifying the application to perform the data placement in the appropriate tiers. libmemkind is commonly used to provide malloc-like interfaces to such applications. The libnuma library provides a lower-level, page-based interface for application-aware memory tiering.
Memory Tiering can also be done in a way that is transparent to applications. A hardware implementation of this is Memory Mode. Software implementations of transparent Memory Tiering include the experimental Linux Memory Tiering, and the MemVerge product.
Do not confuse Memory Tiering with Memory Pooling, which is a different concept. The two concepts can work together, though, for example if memory accessed from a pool has high latency, a platform could use Memory Tiering to cache data from the pooled memory in a lower-latency tier such as local DRAM.
mmap
(POSIX Memory Map System Call)
The POSIX file API includes the ability to memory map a file using the system call mmap.
A memory mapped file appears as a range of virtual memory in the application’s address space, allowing the application to access it like memory with loads and stores. For files on storage, this works because the OS uses paging to bring the contents of a page into DRAM when the application accesses that page. For persistent memory, a PMem-aware file system allows a memory mapped file to access the PMem directly, a feature known as DAX.
Linux persistent memory support includes a new flag to mmap, MAP_SYNC.
A successful DAX mapping with MAP_SYNC means it is safe for applications
to flush their changes to persistence using instructions like CLWB.
Without MAP_SYNC, the only way to ensure persistence is to use standard
flushing system calls like msync.
The Linux man page contains the details on how to use this system call.
The equivalent system call on Windows is MapViewOfFile.
msync
(POSIX Flush System Call)
One principle of the PMem programming model is that standard file APIs work as expected on PMem files. For POSIX systems like Linux, the standard API for memory mapping a file is mmap and the standard way to flush any stores to that range to make them persistent is msync.
On Linux, when a PMem file is successfully DAX mapped using the
MAP_SYNC flag to mmap, it is also
possible to flush stores directly from user space using flush
instructions like CLWB. This is typically much faster
than using the system calls for flushing, but both will work.
msync on POSIX systems is roughly equivalent to FlushViewOfFile on Windows.
Namespace
A namespace is a way to partition capacity into logical devices. It is a similar concept to the way a SCSI storage array can be partitioned into SCSI logical units (LUNs). The NVM Express specification defines how namespaces work on NVMe SSDs, and the ACPI specification defines how namespaces work on NVDIMMs. The NVDIMM version was extended and added to the CXL specification in CXL 2.0 so that PMem on CXL can define namespaces in the same way.
Persistent Memory namespaces are more complex to manage than traditional storage, since the capacity is often interleaved across devices. To manage this, namespaces are defined by storing namespace labels on each device that contributes to a namespace. These labels are stored in a label storage area on each device.
On Linux, the ndctl command provides a product-neutral way to manage namespaces. See the create-namespace command for more details.
ndctl
On Linux systems, the ndctl command provides the management of NVDIMM devices. This command is vendor-neutral, following open standards like the NVDIMM details on the ACPI specification.
Some products may also have a vendor-specific command to perform
additional management tasks. For example, Intel’s Optane PMem
is managed using the command ipmctl.
See the ndctl man pages for details.
NFIT
(NVDIMM Firmware Interface Table)
The ACPI specification defines a table known as the NVDIMM Firmware Interface Table, or NFIT. This table is used to report the existence of persistent memory in the system. When the OS detects this table, it typically triggers the loading of the various modules/drivers that support NVDIMMs.
As the name implies, the NFIT only applies to NVDIMMs. PMem attached to CXL will be found by the OS using the standard PCIe bus enumeration, just like any PCIe devices.
NT Store
(Non-Temporal Store)
The Intel Software Development Manuals (SDM) describe a type of store known as _non-temporal stores* or NT Stores. This excerpt from the manuals describes why they exist:
Data referenced by a program can be temporal (data will be used again) or non-temporal (data will be referenced once and not reused in the immediate future). For example, program code is generally temporal, whereas, multimedia data, such as the display list in a 3-D graphics application, is often non-temporal. To make efficient use of the processor’s caches, it is generally desirable to cache temporal data and not cache non-temporal data. Overloading the processor’s caches with non-temporal data is sometimes referred to as “polluting the caches.” The SSE and SSE2 cacheability control instructions enable a program to write non-temporal data to memory in a manner that minimizes pollution of caches.
For persistent memory, NT stores are additionally
useful as they bypass the CPU cache so that the stores become persistent
without requiring an additional flushing instruction like CLWB.
It is important to note that Intel’s NT stores are write combining rather
than write back like normal memory stores. This means that the stores are
not necessarily globally visible to other threads until a fence
instruction like SFENCE is issued.
Libraries like PMDK make heavy use of NT stores. The libpmem library, for example, uses heuristics to determine a it is better to copy a memory range using write-back-cached instructions or NT stores.
NVDIMM
(Non-Volatile Dual In-line Memory Module)
The JEDEC standards organization defines multiple types of NVDIMM which provide some sort of persistence in the DIMM form factor. For persistent memory, the two types of NVDIMM that can provide the PMem programming model are NVDIMM-N and NVDIMM-P. A third type of PMem in the DIMM form factor is Intel’s Optane PMem, which uses the proprietary DDR-T protocol.
NVM
(Non-Volatile Memory)
In modern usage, the term NVM refers to a class of products that do not lose their contents when power is removed. Compare this to the modern usage of the term [persistent memory(#persistent-memory), which adds attribute that it is load/store accessible. The general term, NVM, can refer to storage like SSDs, or PMem. The more specific term, persistent memory, does not refer to a product that can only be used as block storage.
Optane
(DCPMM, DCPM)
Optane is the brand name for Intel’s product line using
3D XPoint media. The line includes
Optane SSDs, providing the block storage interfaces,
and Optane PMem, providing the PMem programming model.
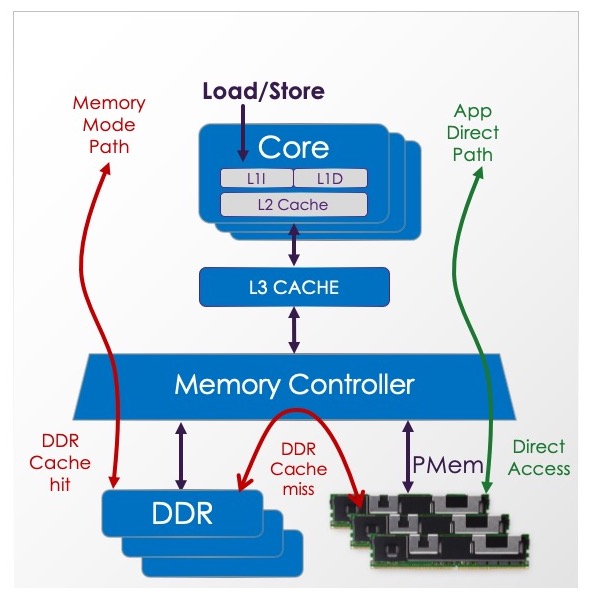 As shown in the diagram above, the Optane PMem product supports a volatile
mode, known as Memory Mode, which uses DRAM as a
cache in front of the PMem. Optane PMem also supports a persistent mode,
known as App Direct, for PMem use cases.
As shown in the diagram above, the Optane PMem product supports a volatile
mode, known as Memory Mode, which uses DRAM as a
cache in front of the PMem. Optane PMem also supports a persistent mode,
known as App Direct, for PMem use cases.
The PMDK libraries are design for PMem programming, so their use with Optane PMem is intended for App Direct mode.
For details on Optane, see Intel’s Optane page.
Paging
When accessing data structures on block storage, paging is used to bring the appropriate blocks into DRAM as required. The paging can be transparent to the application (i.e. kernel paging), or the application can manage the paging itself (the case for most high-end databases).
Persistent memory doesn’t require paging for access, since it is, by definition, byte-addressable. This is an advantage over storage in multiple ways, since the lack of paging means lower latency, consistent latency, and it removes the need to evict other data from DRAM to make room for the inbound pages. However, some PMem-aware applications may still move blocks between PMem and DRAM to leverage the higher performance of DRAM for hot data.
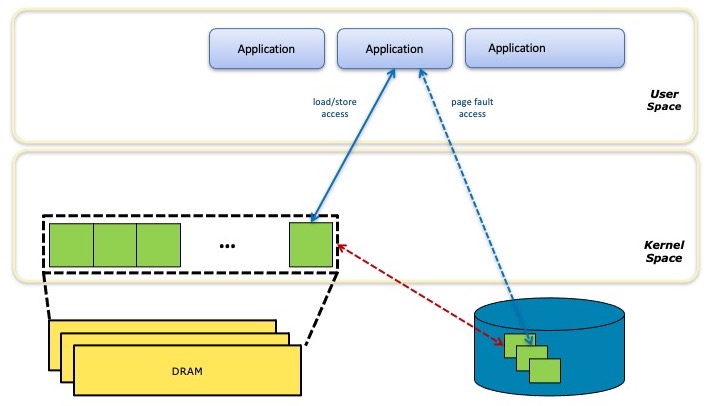
The diagram above illustrates how a storage-based memory mapped file is implemented with paging. The application accesses the file data in DRAM as if it were byte-addressable, but when there’s a page cache miss, the system suspends the application while it moves the page from block storage into DRAM, potentially evicting another page first to make room.
PCJ
(Persistent Collections for Java)
PCJ is an experimental Library providing persistent collections for Java. More information can be found on the PCJ GitHub Page.
Persistence Domain
(Power Fail Safe Domain)
The term Persistence Domain refers to the portion of the data path where a store operation is considered persistent by software. For ADR systems, the persistence domain is the memory controller – applications can assume a store is persistent once it has been accepted by the memory sub-system. For eADR systems, the persistence domain is reached when a store reached global visibility.
Persistent Memory
(PMem, pmem, PM)
The SNIA NVM Programming Technical Workgroup defined persistent memory in their paper defining the PMem programming model:
storage technology with performance characteristics suitable for a load and store programming model
For a device to be considered persistent memory, it must support the load/store programming model and be fast enough that it is reasonable for software use it that way.
The full SNIA NVM Programming Specification contains more detail on persistent memory semantics.
PMDK
(Persistent Memory Development Kit)
The Persistent Memory Development Kit, or PMDK is a growing collection of libraries and tools with the stated goal of making persistent memory programming easier. Tuned and validated on both Linux and Windows, the libraries build on the DAX feature of those operating systems (short for Direct Access) which allows applications to access persistent memory as memory-mapped files, as described in the SNIA NVM Programming Model.
The source for PMDK is spread across multiple
GitHub repositories.
 The PMDK libraries fit into the PMem programming model
as shown in the diagram, where applications pull in just
what they need from PMDK, but otherwise continue to
use the direct access provided by the model.
The PMDK libraries fit into the PMem programming model
as shown in the diagram, where applications pull in just
what they need from PMDK, but otherwise continue to
use the direct access provided by the model.
Since the normal file APIs work with PMem, the application could use them, or use any library build on storage APIs. However, those APIs are all buffer based, requiring data copies into and out of DRAM buffers supplied by the application. PMDK libraries are designed to provide features like allocation and transactions, while still allow the application direct load/store access to its data structures.
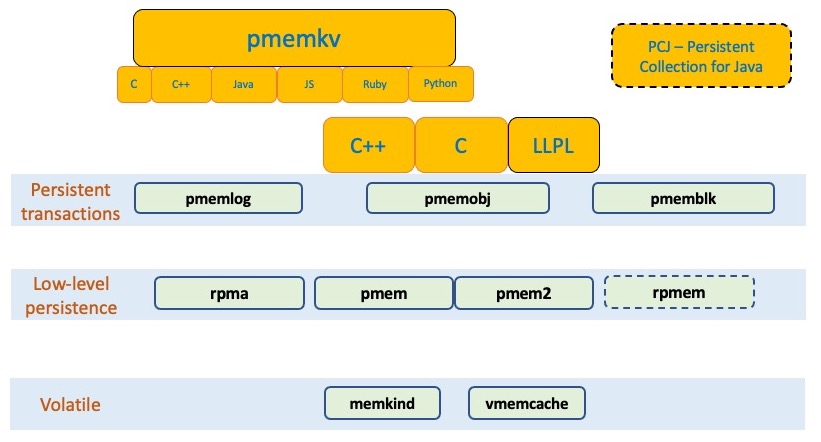
The diagram above shows a quick overview of most of the PMDK libraries. The volatile libraries use PMem for its capacity, but provide no persistence – the memkind library is the most common for volatile use cases.
Low level libraries, like libpmem2 provide basic data movement and cache flushing. The higher level libraries are built on top of them.
The most flexible and commonly-used library is libpmemobj.
The pmemkv libraries provide the highest-level, easiest to use interfaces in the form of a PMem-aware key-value store.
The PMDK web page contains detailed information on the libraries and how to use them.
PMem Programming Model
See programming model for details about the PMem programming model.
pmemhackathon
(Persistent Memory Programming Workshop)
A series of workshops about programming with persistent memory have been held over the years, often referred to as PMem Hackathons. Each workshop includes a series of fully-functional examples, meant to me used as starting points for PMem programming. The archive of these workshop examples is at pmemhackathon.io, each named after the date of the workshop.
PMoF
(Persistent Memory over Fabrics)
The term PMoF has been used in the past to refer to using RDMA to access remote persistent memory. The newer term, rpmem is now more commonly used.
Poison
On Intel servers, a special poison value is returned when accessing a memory location that has experienced data loss, such as an uncorrectable error. Consuming poison triggers a machine check event, which the kernel will turn into an exception to the application consuming the poison if possible (it isn’t possible if the poisons is consumed by the kernel itself, which is can cause a system crash, if the kernel has no way to recover).
For more information about how poison impacts persistent memory aware applications, see the entry on uncorrectable errors and on the blast radius concept.
Pool
A pool is a PMDK concept which refers to an allocation of some persistent memory capacity by the system. A pool is often just a file on a PMem-aware file system, available for use with the PMDK libraries. The term pool is used instead of file because sometimes a pool may consist of multiple files (see the entry on poolset), and sometimes a pool may be a device DAX device. The application using PMDK has these differences abstracted away, depending on the pool concept instead of having to deal with all the ways the capacity might be presented to PMDK.
Poolset
A poolset is a PMDK concept where multiple files or device DAX devices are combined and used as a single, logical pool. Poolsets also support replication that is application transparent (at least until a failure occurs and administrative actions are required).
See the poolset man page for details.
Programming Model
The term programming model can refer to multiple aspects of persistent memory.
At the lowest level, the programming model describes how to interface with the hardware. For persistent memory, the interface is similar to system memory, where accesses happen with load and store CPU instructions. At this level, persistence domain is also defined. For example, on Intel hardware, instructions like CLWB are used to make stores persistent and features like ADR and eADR define how and when those instructions are used.
Another use of the term programming model is to describe how applications get access to persistent memory from the OS. This is where the SNIA NVM Programming Model applies.
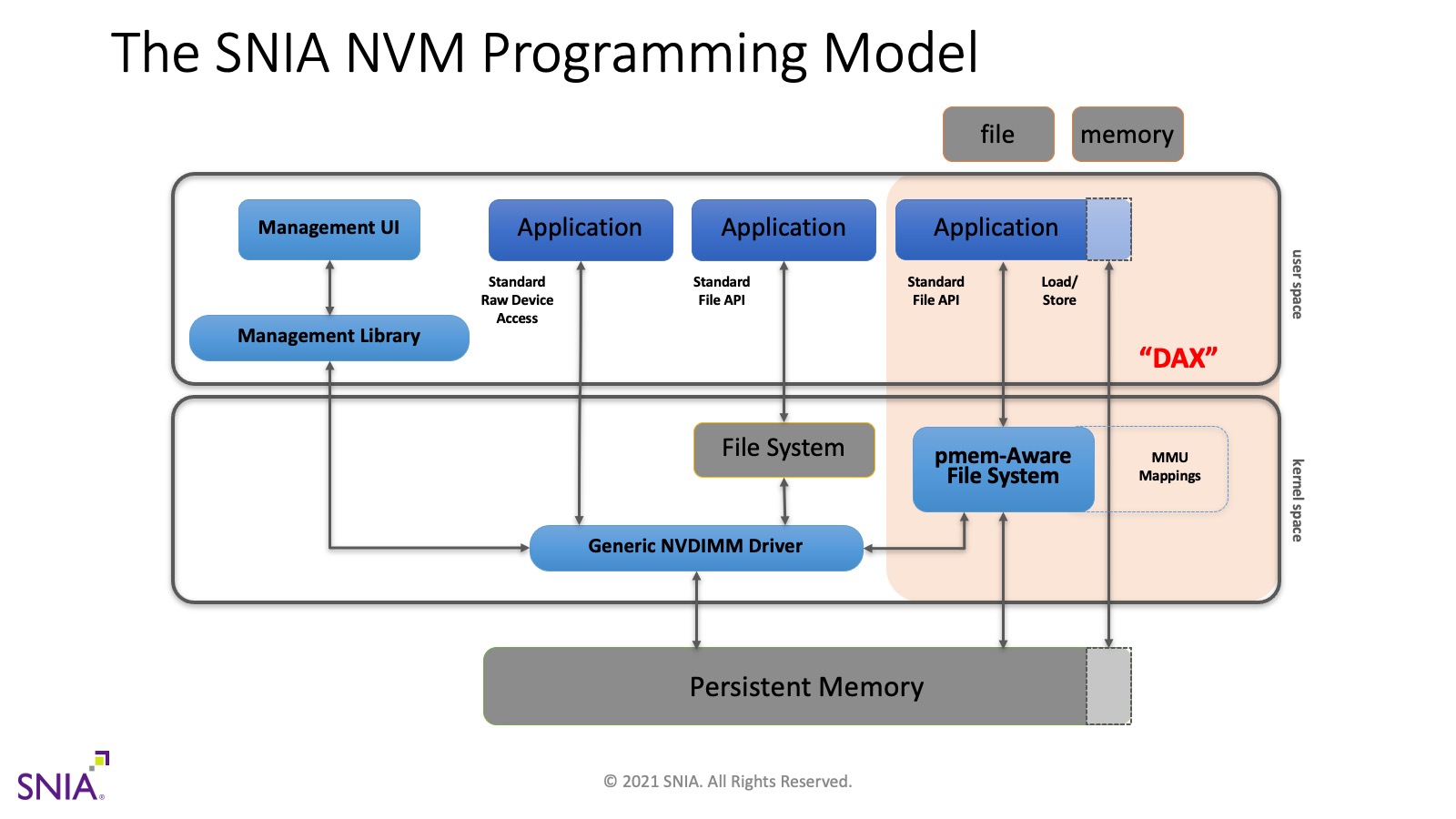
As shown in the diagram above, the PMem programming model is a generic, OS- and vendor-neutral model, where persistent memory is managed by a kernel driver (called Generic NVDIMM Driver in the diagram). That driver provides access for managing the PMem’s health and configuration (the left path). It also provides access for standard block storage interfaces (the middle path), so that file systems and applications designed for traditional storage will work without modification. The right path is focus of most persistent memory programming, where a PMem-aware file system exposes PMem as files.
The definition of a PMem-aware file system is a file system that bypasses the system page cache when a file is memory mapped. This means applications can map the PMem file using standard APIs like mmap on Linux and MapViewOfFile on Windows, and the result will be a DAX mapped file, giving the application direct load/store access to the persistent memory itself. Unlike memory mapped files on storage, where the OS performs paging to DRAM as necessary, the application is able to access persistent memory data structures in-place, right where they are located in PMem.
The PMDK libraries build on top of this programming model to provide more convenient abstractions for working with persistent memory. This environment at the application level, where there are tools and libraries available, is often described using the term programming model as well. This means we’ve described three definitions of the term programming model (the interface to the hardware, the way the OS exposes PMem, and the full programming environment available to the application). All of these usages of the term are valid, but the most common use is to refer to the SNIA model described above.
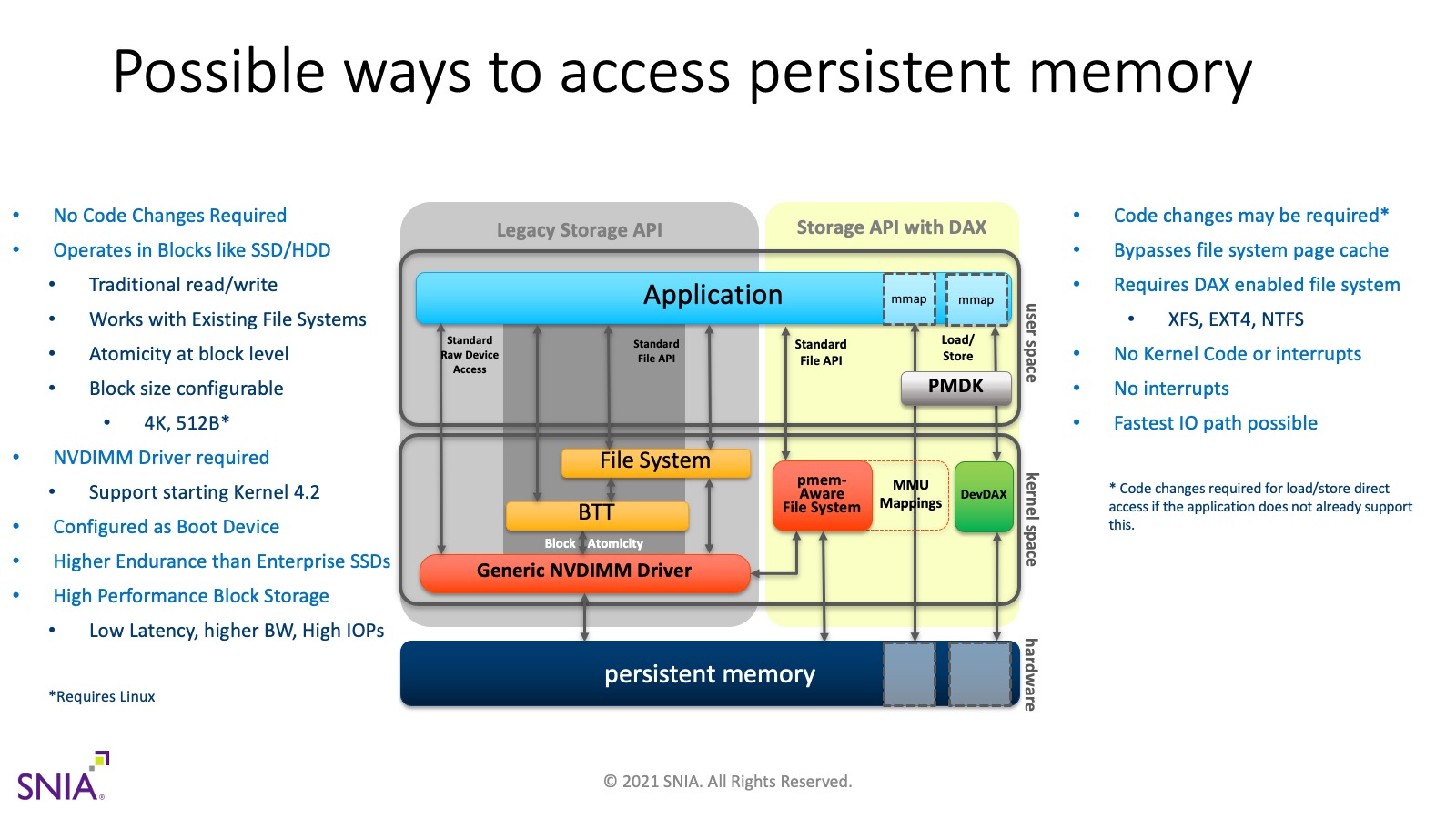
In addition to the PMem programming model described above, Linux systems provide an alternative called device DAX. The diagram below summarizes the various ways available to access persistent memory.
Region
A region is another term for interleave set. The Linux tools, such as ndctl use this term, as does the CXL specification.
RPMEM
(Remote Persistent Memory)
Since PMem is accessible like memory, technologies that work directly with memory also work with PMem. RDMA is an exciting example of this, allowing low-latency, direct access to remote persistent memory.
The PMDK library librpma was designed to help applications use RDMA with persistent memory.
One major application that has published impressive results around RPMEM is Oracle Exadata, as described in their blog.
SNIA
(Storage Networking Industry Association)
According to the SNIA website, their mission statement is:
Lead the storage industry worldwide in developing and promoting vendor-neutral architectures, standards, and educational services that facilitate the efficient management, movement, and security of information.
For persistent memory, SNIA played a central role in defining the PMem programming model which is described by the NVM Programming Specification.
Storage Class Memory
(SCM)
The term Storage Class Memory is a synonym for persistent memory. The SNIA documentation prefers the term persistent memory but both terms are found in academic papers on the topic.
Transaction
In the world of persistent memory programming, transactions are a common tool to maintain a consistent persistent data structure. Traditionally, programmers are familiar with the need to maintain consistent data structures on storage, such as a database stored on a disk. Techniques such as write ahead logging are often used to ensure the database is in a consistent state in the face of unexpected failure such as a system crash or power failure.
For data structures in traditional DRAM, application programmers are familiar with multi-threaded programming techniques, to ensure each thread sees a consistent state when accessing the data structure. But if the program crashes or the system looses power, those DRAM-resident data structures are gone so there’s no need for logging like the above database example.
Persistent memory brings these two worlds together: a persistent memory resident data structure is often covered by multi-threaded programming techniques, as well as transaction/logging techniques to ensure consistency of the persistent data structure in the face of failure. Since PMem is load/store accessible, it is possible to implement transactions in a much more optimal and fine-grained manner than with block storage.
The PMDK library libpmemobj provides support for arbitrary transactions on PMem-resident data structures.
Uncorrectable Error
When a storage device experiences an uncorrectable error, it typically results in an error passed back to applications when they use the storage APIs to access the lost data. But for persistent memory, such errors behave more similarly to DRAM than to storage.
When a server application reads a memory location containing an uncorrectable error, the system must cause an exception to prevent the application from consuming corrupted data. On Intel servers, the CPU is sent a poison value to indicate the lost data, and when poison is consumed by software, Intel servers generate a machine check exception. This exception allows the kernel to raise an exception to the application, such as sending a Linux application a SIGBUS signal. Under some cases, a machine check is fatal to the system and it crashes as a result (an example of this is when the kernel itself is the consumer of the poison).
Persistent memory aware applications will experience uncorrectable errors in PMem much like they do for DRAM. The difference is that when an application crashes due to a DRAM uncorrectable error, that location is gone when the application restarts – volatile memory always starts out new and the contents from previous runs is not expected to stay around.
Obviously, PMem is different and the contents are designed to stay around. Thus, if an application crashes due to an uncorrectable error in PMem, it may very well try to access the same location again after restarting, and crash again due to the same uncorrectable. This leads to more complex requirements on PMem-aware applications in order to avoid these crash loops. To help this situation, the system may provide a list of known bad blocks, so that an application can avoid accessing those areas. The application architect must also be aware of the blast radius of uncorrectable errors, which may result in more data loss than a single memory location when they occur.
This article on Optane RAS contains more details on this topic.